Sincronización de relojes
Un sistema distribuido debe permitir el apropiado uso de los recursos, debe encargarse de un buen desempeño y de la consistencia de los datos, además de mantener seguras todas estas operaciones La sincronización de procesos en los sistemas distribuidos resulta más compleja que en los centralizados, debido a que la información y el procesamiento se mantienen en diferentes nodos. Un sistema distribuido debe mantener vistas parciales y consistentes de todos los procesos cooperativos y de cómputo. Tales vistas pueden ser provistas por los mecanismos de sincronización. El término sincronización se define como la forma de forzar un orden parcial o total en cualquier conjunto de eventos, y es usado para hacer referencia a tres problemas distintos pero relacionados entre sí:
1. La sincronización entre el emisor y el receptor.
2. La especificación y control de la actividad común entre procesos cooperativos.
3. La serialización de accesos concurrentes a objetos compartidos por múltiples procesos. Haciendo referencia a los métodos utilizados en un sistema centralizado, el cual hace uso de semáforos y monitores; en un sistema distribuido se utilizan algoritmos distribuidos para sincronizar el trabajo común entre los procesos y estos algoritmos
La sincronización de relojes en un sistema distribuido consiste en garantizar que los procesos se ejecuten en forma cronológica y a la misma vez respetar el orden de los eventos dentro del sistema. Para lograr esto existen varios métodos o algoritmos que se programan dentro del sistema operativo, entre los cuales tenemos:
- Algoritmo de Cristian
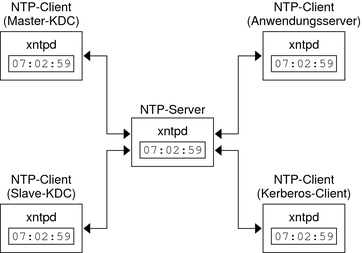
Este algoritmo está basado en el uso del tiempo coordenado universal (siglas en inglés, UTC), el cual es recibido por un equipo dentro del sistema distribuido. Este equipo, denominado receptor de UTC, recibe a su vez solicitudes periódicas del tiempo del resto de máquinas del sistema a cada uno de los cuales les envía una respuesta en el menor plazo posible informando el tiempo UTC solicitado, con lo cual todas las máquinas del sistema actualicen su hora y se mantenga así sincronizado todo el sistema. El receptor de UTC recibe el tiempo a través de diversos medios disponibles, entre los cuales se menciona las ondas de radio, Internet, entre otros. Un gran problema en este algoritmo es que el tiempo no puede correr hacia atrás:
El tiempo del receptor UTC no puede ser menor que el tiempo de la máquina que le solicitó el tiempo.
El servidor de UTC debe procesar las solicitudes de tiempo con el concepto de interrupciones, lo cual incide en el tiempo de atención.
El intervalo de transmisión de la solicitud y su respuesta debe ser tomado en cuenta para la sincronización. El tiempo de propagación se suma al tiempo del servidor para sincronizar al emisor cuando éste recibe la respuesta.
- Algoritmo de Berkeley
Un sistema distribuido basado en el algoritmo de Berkeley no dispone del tiempo coordenado universal (UTC); en lugar de ello, el sistema maneja su propia hora. Para realizar la sincronización del tiempo en el sistema, también existe un servidor de tiempo que, a diferencia del algoritmo de Cristian, se comporta de manera activa. Este servidor realiza un muestreo periódico del tiempo que poseen algunas de las máquinas del sistema, con lo cual calcula un tiempo promedio, el cual es enviado a todas las máquinas del sistema a fin de sincronizarlo.
Sincronización en sistemas distribuidos
El problema que existe en un sistema distribuido, es determinar el orden particular sobre cualquier conjunto de eventos en un sistema distribuido. Existen dos grupos de mecanismos de sincronización: centralizados y distribuidos.
Mecanismos de sincronización centralizada
Estos son los mecanismos que se basan en la existencia de una unidad de sincronización centralizada, la cual debe tener un nombre único conocido para todos los procesos que requieren ser sincronizados. Se designa un nodo como nodo de control y su tarea es administrar el acceso a los recursos compartidos. Este nodo también almacena información relevante sobre todos los procesos que realizan alguna petición. A continuación se hace una distinción de diferentes mecanismos centralizados.
Algoritmos no basados en paso de mensajes
Algoritmo de Lamport. Fue el primer algoritmo propuesto para lograr la exclusión mutua en redes cuyos nodos se comuniquen solamente mediante mensajes y que no compartan memoria. Fue propuesto por Lamport en 1978. El objetivo de la propuesta de Lamport es obtener un algoritmo que cumpla con las siguientes condiciones:
•Un proceso que posee a un recurso, debe liberarlo antes de que sea otorgado a otro proceso.
•Se deben entregar los derechos sobre un recurso en el orden en que se hicieron todas las solicitudes de uso del recurso. A continuación se describe el algoritmo para resolver la exclusión mutua (por conveniencia, se asume que las acciones definidas por cada regla son para un solo evento).
Reloj Físico
La idea es proveer de un único bloque de tiempo para el sistema. Los procesos pueden usar la marca física del tiempo provista o leída de un reloj central para expresar algún orden en el conjunto de acciones que inician. La principal ventaja de este mecanismo es la simplicidad, aunque existen varios inconvenientes: el correcto registro del tiempo depende en la posibilidad de recibir correctamente y en todo momento, el tiempo actual desplegado por el reloj físico; los errores de transmisión se convierten en un impedimento para el orden deseado, el grado de exactitud depende de las constantes puestas en el sistema.
· Los valores de tiempo asignados a los eventos no tienen porqué ser cercanos a los tiempos reales en los que ocurren.
· En ciertos sistemas es importante la hora real del reloj:
Ø Se precisan relojes físicos externos (más de uno).
Ø Se deben sincronizar:
v Con los relojes del mundo real.
v Entre sí.
Sincronización de relojes Físicos
Para conocer en qué hora del día ocurren los sucesos en los procesos de nuestro sistema distribuido Q, es necesario sincronizar los relojes de los procesos con una fuente de tiempo externa autorizada. Esto es la SINCRONIZACIÓN EXTERNA. Y si los relojes están sincronizados con otro con un grado de precisión conocido, entonces podemos medir el intervalo entre dos eventos que ocurren en diferentes computadores llamando a sus relojes locales, incluso aunque ellos no estén necesariamente sincronizados con una fuente externa de tiempo. Esto es SINCRONIZACION INTERNA. Definimos estos dos modos de sincronización mas detalladamente, sobre un intervalo de tiempo real I: deduce de las definiciones que si el sistema Q está sincronizado externamente con un límite D entonces el mismo sistema esta sincronizado internamente con un límite 2D.
Tiempo Lógico y Relojes Lógicos
Los relojes lógicos son aquellos por los cuales están ordenados los sucesos de una forma única. Para poder usar en general el tiempo físico se debe sincronizar perfectamente bien los relojes a lo largo de un sistema distribuido para poder así obtener el orden de cualquier par arbitrario de sucesos que ocurran en el, pero es poco probable que esto ocurra por qué no se puede sincronizar perfectamente los relojes a lo largo de un sistema distribuido. Se puede utilizar un esquema que similar a la casualidad física, que se aplica en los sistemas distribuidos, para controlar el orden de algunos sucesos que ocurren en diversos procesos. La cual está basada en dos puntos sencillos y obvios. Cuando se envía un mensaje entre procesos, el suceso de enviar el mensaje ocurrió antes del de recepción del mismo. Lamport llamo a la ordenación obtenida al generalizar estas dos relaciones la realización suceder antes. También se le conoce como la relación de orden casual o ordenación casual del mismo. La relación captura un flujo de información entre dos eventos. La información puede fluir de formas distintas de la de paso de mensajes. Por ejemplo: Si Pérez presenta un mandato a su proceso para que envíe un mensaje, acto seguido telefonea a Gómez, quien ordena a su proceso que envíe otro mensaje, luego el envío del primer mensaje claramente sucedió antes que el segundo. Desafortunadamente, como no se ha enviado mensajes de red entre los procesos que los emitieron, no podemos modelar este tipo de relaciones en nuestro sistema. Otro punto a señalar es que aun produciéndose la relación sucedió antes entre dos sucesos, el primero podría o no haber causado realmente el segundo. Un proceso podría recibir un mensaje y consecuentemente enviar otro mensaje, pero no que él emite cada cinco minutos en cualquier caso y no tiene ninguna relación específica con el primer mensaje. No se ha supuesto ninguna causalidad real, pero la relación debe ordenar estos sucesos.
Lamport invento un mecanismo simple con el cual la relación sucedió antes pueda capturarse numéricamente, denominado reloj lógico. Un reloj es un contador software que se incrementa monotonamente, y sus valores no necesitan tener relación alguna con el reloj físico.
Algunos pares de sucesos distintos, generados por diferentes procesos, tienen marcas de tiempo de Lamport numéricamente idénticas. Sin embargo, podemos crear un orden, uno para el que todos los pares de sucesos distintos están ordenados, teniendo en cuenta los identificadores de los procesos en los que ocurren los sucesos. Lamport la utilizo, para ordenar la entrada de procesos en una sección.
Relojes Vectoriales
Mattern y Fidge desarrollaron relojes vectoriales para mejorar la deficiencia de los relojes de Lamport, del hecho que no podemos deducir que un reloj vectorial para un sistema de N procesos es un vector de N enteros. Cada proceso mantiene su propio reloj vectorial Vi, que utiliza para colocar marcas de tiempo en los sucesos locales. Como las marcas de tiempo de Lamport, cada proceso adhiere el vector de marcas de tiempo en los mensajes que envía al resto, y hay unas reglas sencillas para actualizar los relojes. Los vectores de marcas de tiempo tienen la desventaja, comparados con las marcas de tiempo de Lamport, de precisar una cantidad de almacenamiento y de carga real de mensajes que es proporcional a N, el número de procesos.
Requisitos para la Exclusión Mutua
Requisitos para la Exclusión Mutua
Los recursos no compartibles, ya sean periféricos, ficheros, o datos en memoria, pueden protegerse del acceso simultáneo por parte de varios procesos evitando que éstos ejecuten de forma concurrente sus fragmentos de código a través de los cuales llevan a cabo este acceso. Estos trozos de código reciben el nombre de secciones o regiones críticas, pudiéndose asimilar el concepto de exclusión mutua en el uso de estos recursos a la idea de exclusión mutua en la ejecución de las secciones críticas. Así, por ejemplo, puede implementarse la exclusión mutua de varios procesos en el acceso a una tabla de datos mediante el recurso de que todas las rutinas que lean o actualicen la tabla se escriban como secciones críticas, de forma que sólo pueda ejecutarse una de ellas a la vez. En el ejemplo previo de la cuenta bancaria los fragmentos de código a1a2a3 y b1b2b3 constituyen dos secciones críticas mutuamente excluyentes, esto significa que una vez que se ha comenzado la ejecución de una sección crítica, no se puede entrar en otra sección crítica mutuamente excluyente.
Idear soluciones que garanticen la exclusión mutua es uno de los problemas fundamentales de la programación concurrente. Muchas son las alternativas y tipos de mecanismos que se pueden adoptar. A lo largo de este tema veremos diferentes soluciones software y alguna hardware ; unas serán sencillas y otras complejas, algunas requieren la cooperación voluntaria de los procesos y otras que exigen un estricto ajuste a rígidos protocolos. La selección de las operaciones primitivas adecuadas para garantizar la exclusión mutua de las secciones críticas es una decisión primordial en el diseño de un sistema operativo. Al menos, una solución apropiada debería cumplir las cuatro condiciones siguientes:
1. Que no haya en ningún momento dos procesos dentro de sus respectivas secciones críticas.
2. Que no hagan suposiciones a priori sobre las velocidades relativas de los procesos o el número de procesadores disponibles.
3. Que ningún proceso que esté fuera de su sección crítica pueda bloquear a otros.
4. Que ningún proceso tenga que esperar un intervalo de tiempo arbitrariamente grande para entrar en su sección crítica.
No hay comentarios:
Publicar un comentario